Case Study · 民眾應用
ClinCalc
民眾健康自查與多模態解讀平台
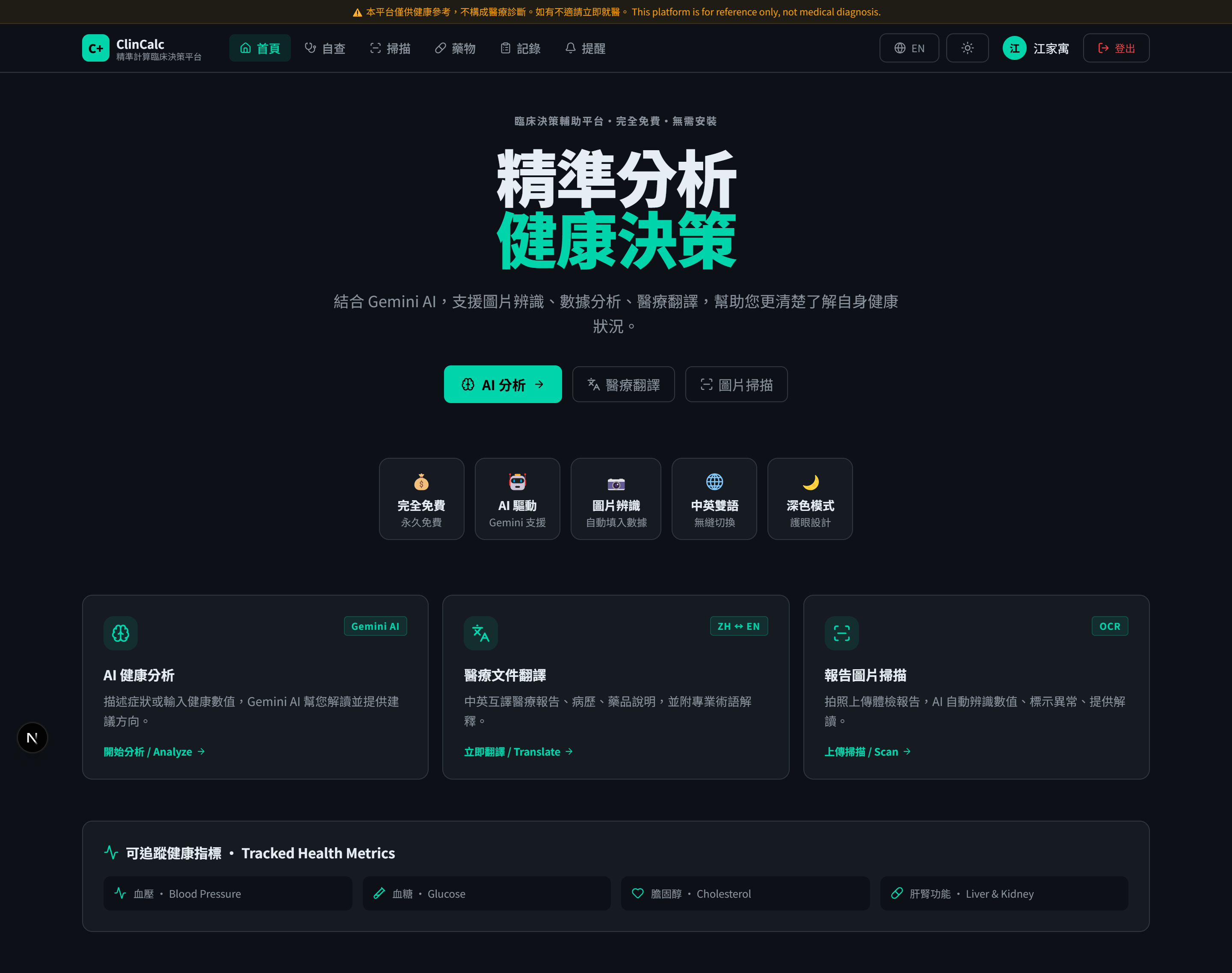
痛點
很多民眾拿到體檢報告,看著一堆數字與專有名詞,不知道哪些代表問題、哪些可以暫時不理會。 一般人會做的事是上網查、問家人、或乾脆忽略。這之中有兩個結構性問題:
- 資訊不對等 ── 醫療術語對普通人不友善
- 隱私顧慮 ── 把檢驗數值貼到 ChatGPT 不安全
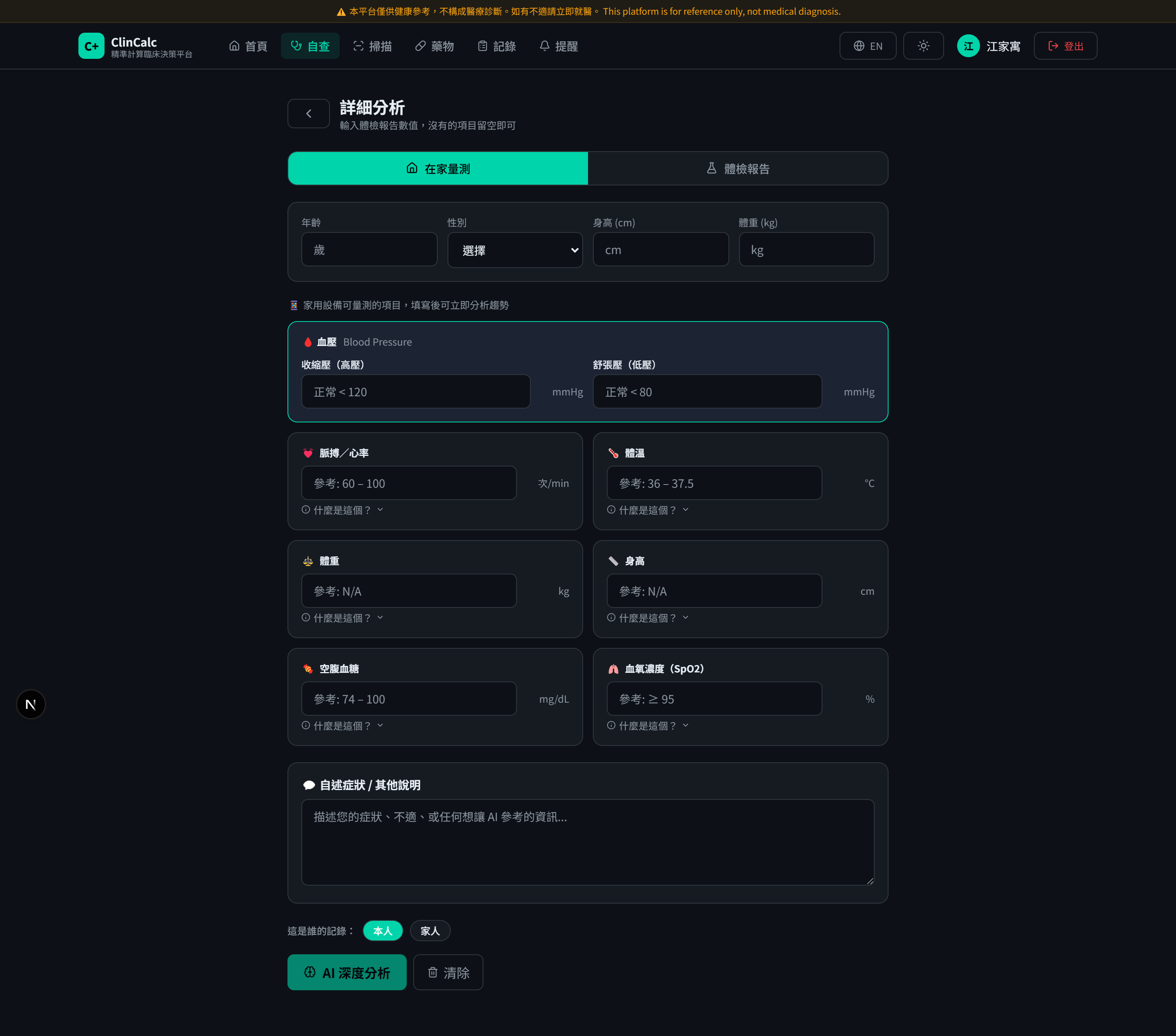
系統架構
「先規則後 LLM」三層架構:本地判定 → 結構化注入 → LLM 翻譯。原始病人資料不離本地。
- 1 · 使用者輸入
填入 45 項指標、上傳檢驗報告影像、或在身體地圖點選症狀。
- 2 · 瀏覽器內本地規則引擎
查
referenceRanges.ts知識庫,每項指標即時判定為「正常 / 偏高 / 偏低 / 嚴重偏高 / 嚴重偏低」。原始數值不離開瀏覽器。 - 3 · Cloudflare Worker(邊緣節點)
接收結構化判定(非原始數值),組成 Gemini prompt。免費 100K req/day 足以支援預期流量。
- 4 · Google Gemini 1.5 Flash
翻譯醫療術語、OCR 影像。LLM 看到的是「CKD G3a」結果,不是「江先生的 eGFR=45」。
- 5 · Supabase(PostgreSQL + Auth)
使用者帳號、用藥提醒、健康記錄歷程,受 RLS 保護。
設計亮點 1 ── 先規則後 LLM
ClinCalc 在整合 Gemini 時採取「先查知識庫、再交給 LLM」策略:使用者填完 45 項指標,前端逐一查
referenceRanges.ts 知識庫,對每個欄位呼叫 checkAbnormal() 判定 5 級狀態,
然後把結構化判定結果組成 prompt 交給 Gemini。Gemini 不需要記憶各項指標的正常範圍 ── 降低幻覺。
Trade-off
- 規則覆蓋率有限:模糊的綜合判斷(「我這個報告整體看起來怎樣?」)規則引擎處理不了,LLM 也被限制不能自由生成 → 使用者覺得「能做的事少」
- 規則庫靠手動更新:KDIGO 從 2012 升 2024 是手工改 reference 表
設計亮點 2 ── 多模態模型介入點
Gemini 1.5 Flash 的多模態能力受限於兩個明確的「翻譯」任務 ── 不做臨床判斷:
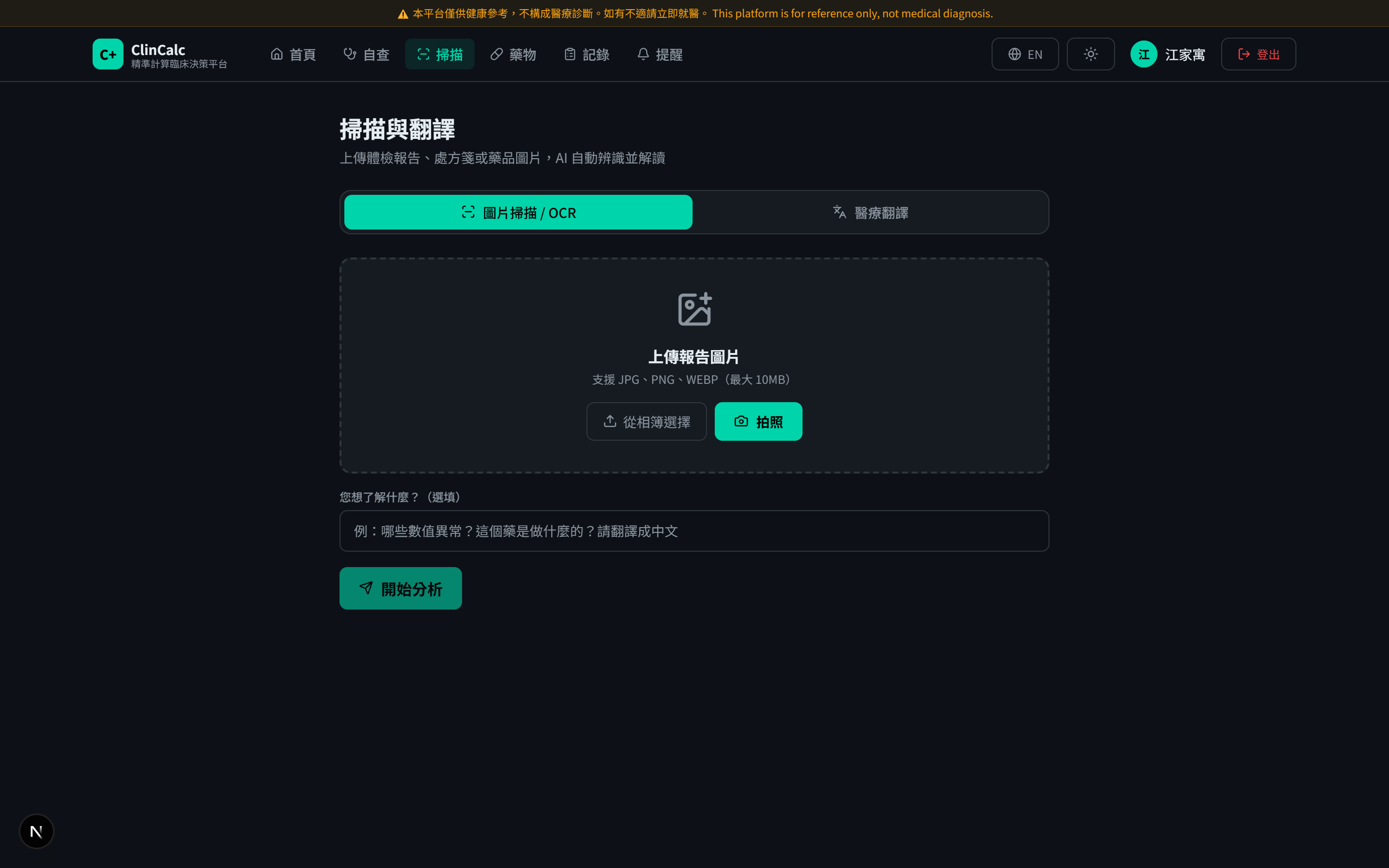
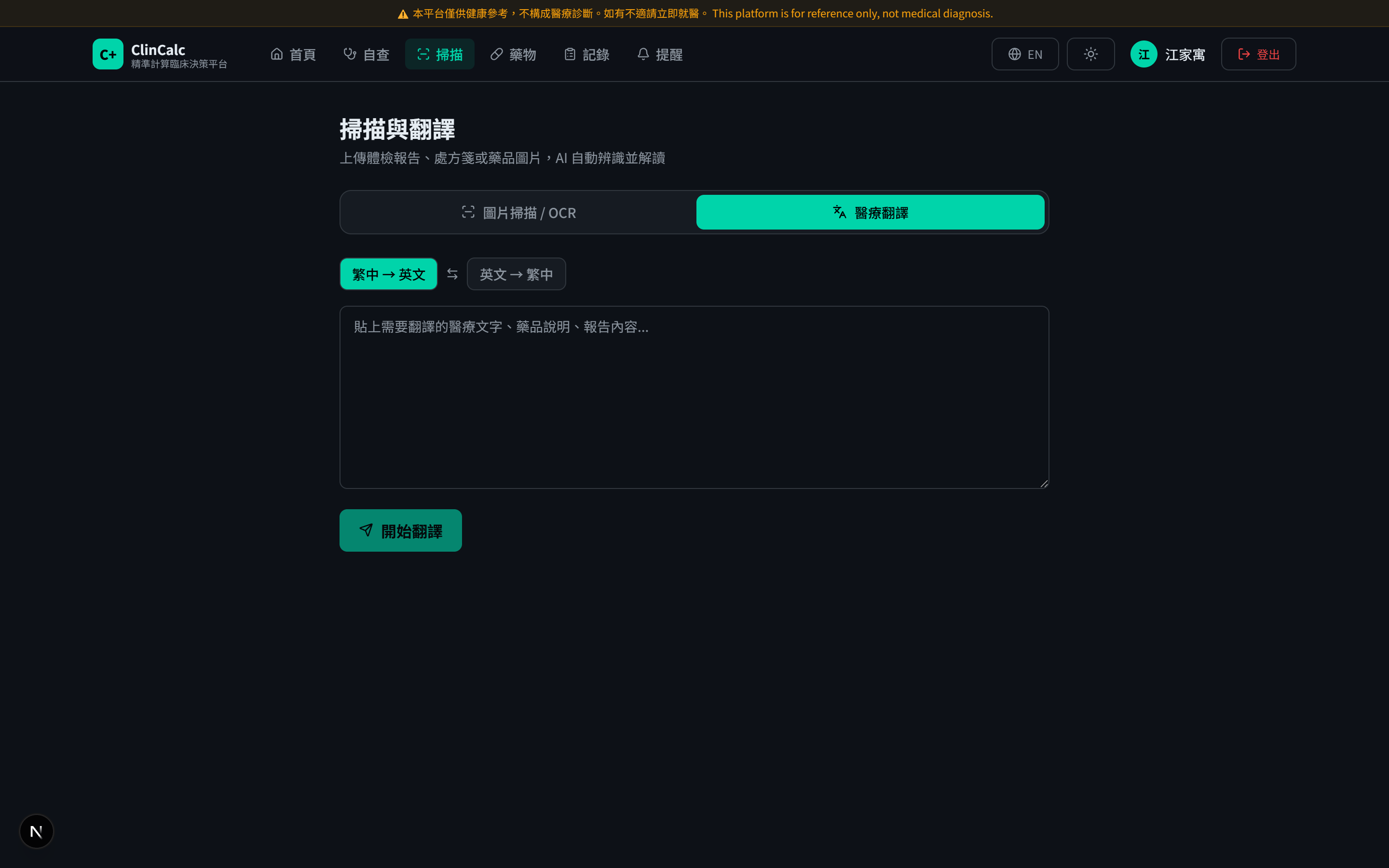
Trade-off
OCR 對手寫報告辨識率仍低(< 70%);翻譯對冷門縮寫偶有偏差。前端對模型輸出做引用驗證 + 異常顯示「需醫師確認」標籤。
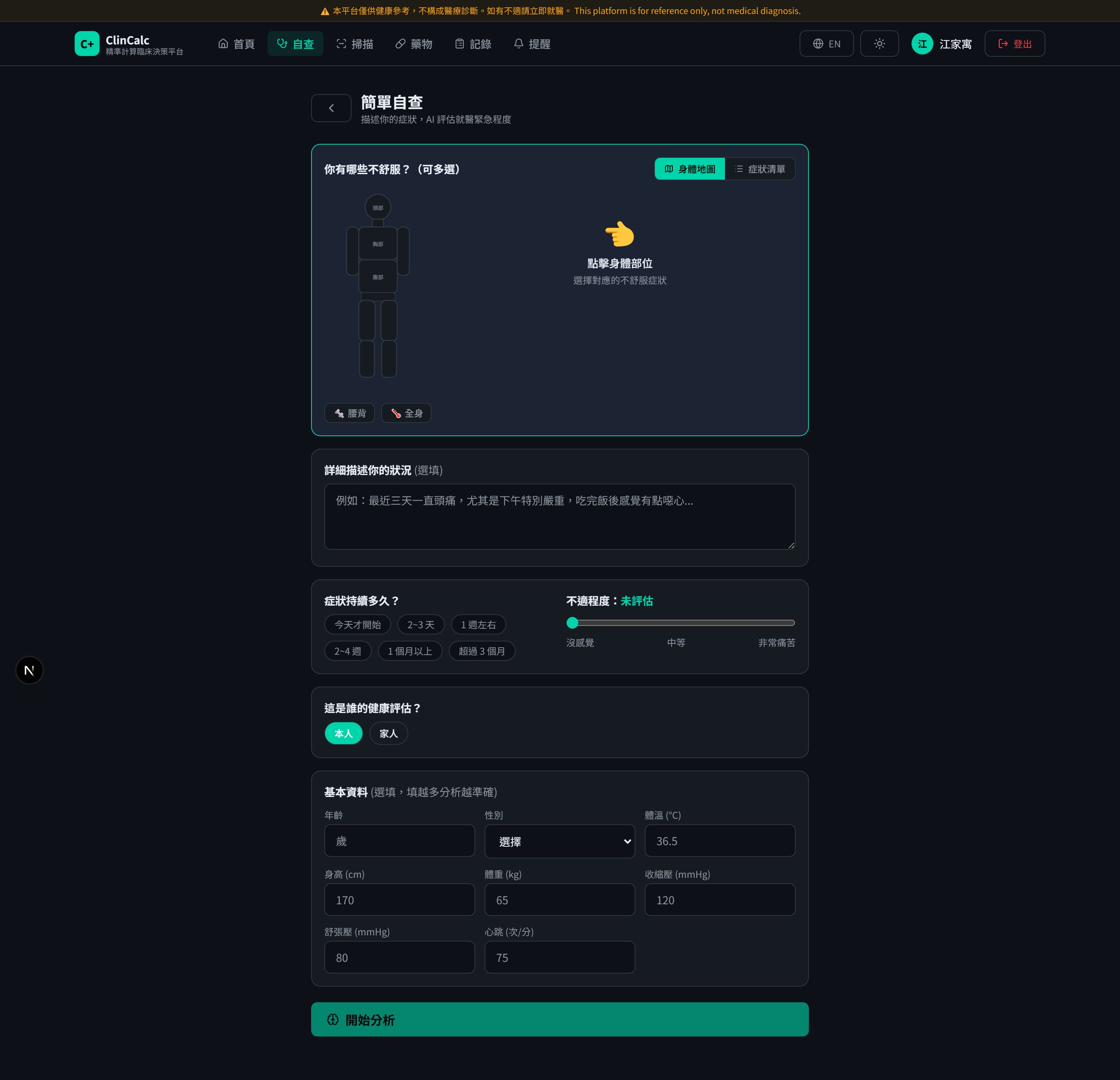
設計亮點 3 ── 互動式症狀探索
傳統症狀檢索是「打字找關鍵字」。ClinCalc 改用視覺地圖:點身體區域 → 展開該區常見症狀 → Gemini 提供初步病因排序與紅旗症狀提示。
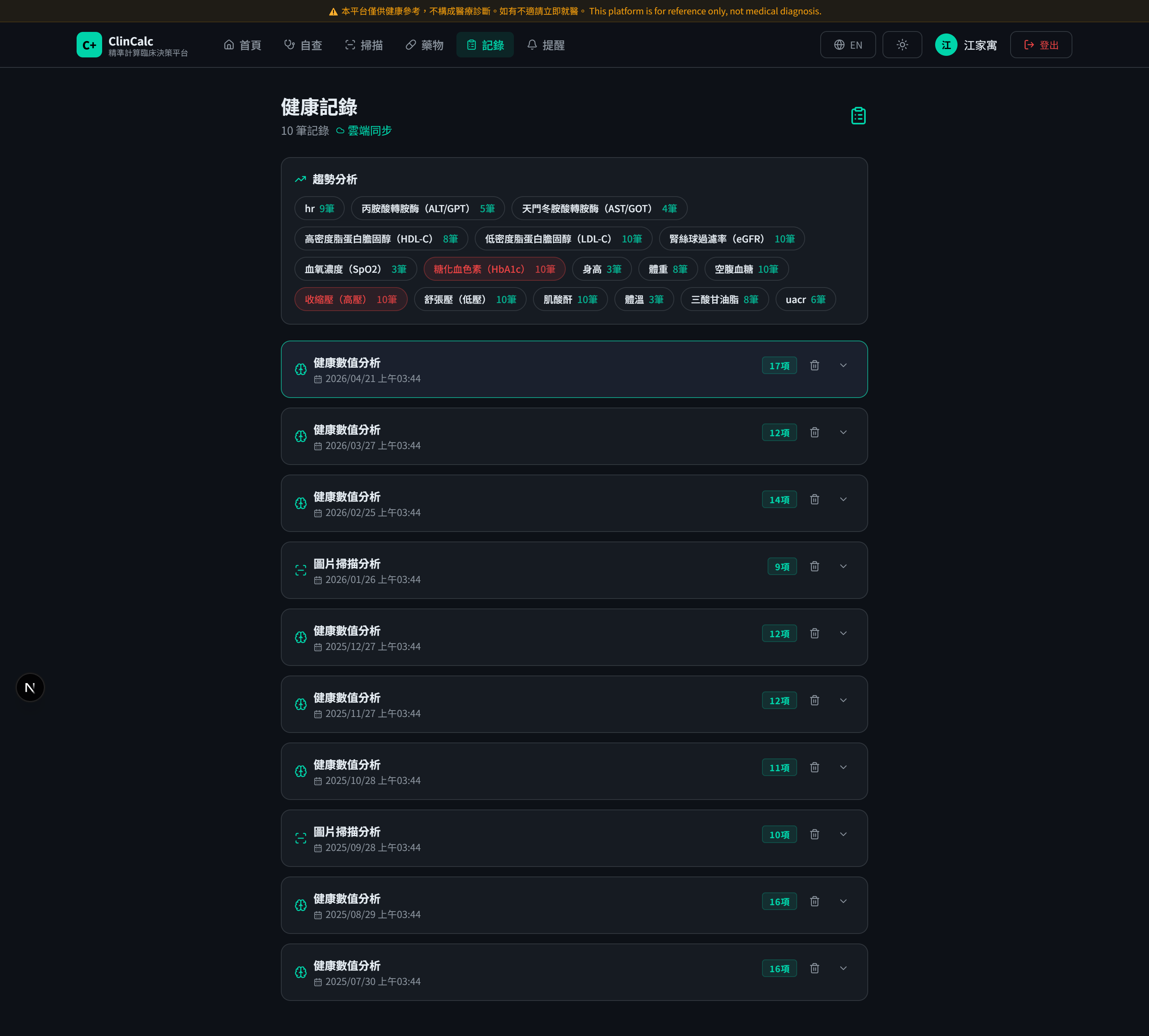
衍生功能:個人健康追蹤
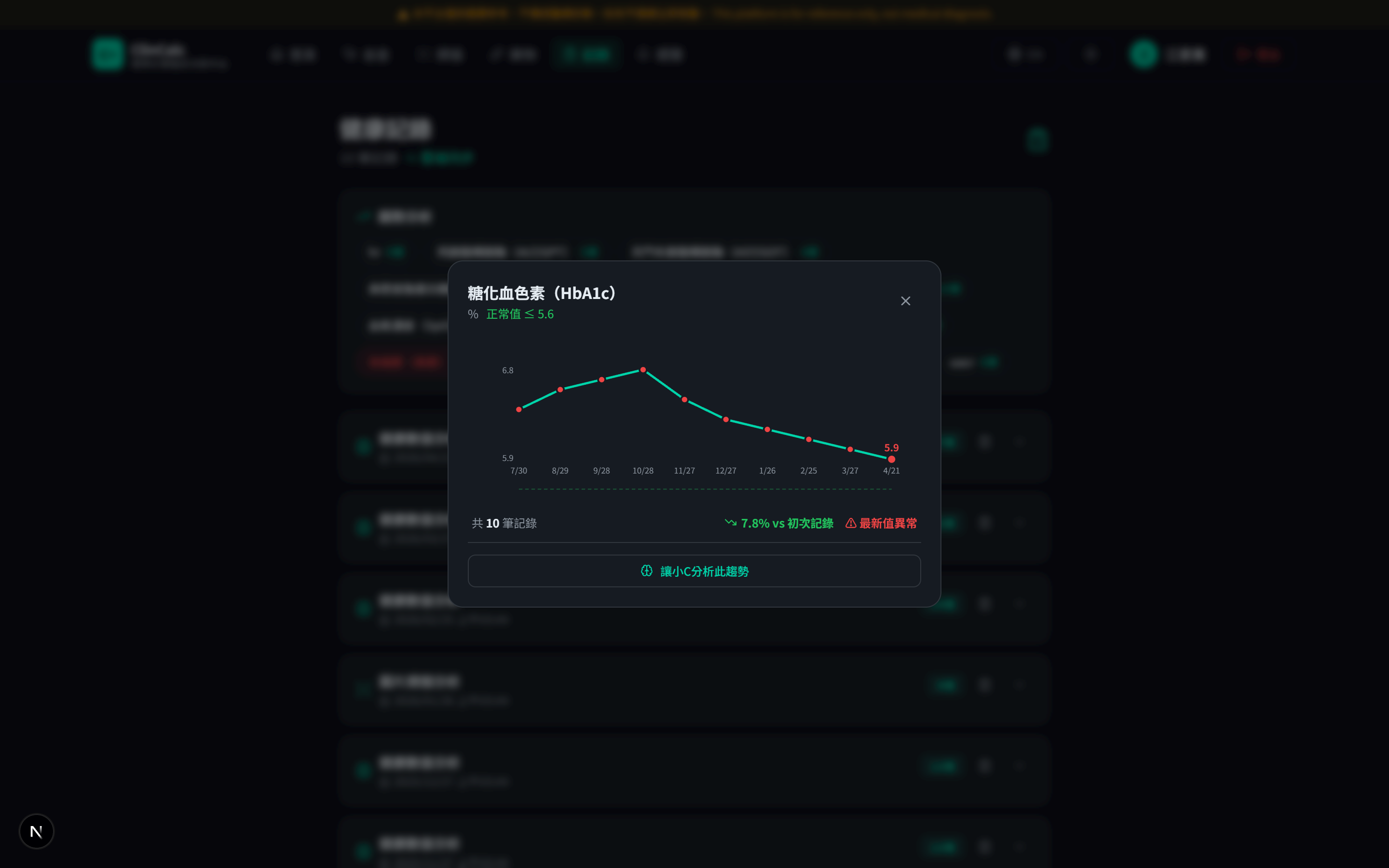
判讀完成後系統會把結果存入 Supabase(受 RLS 保護),形成個人時序紀錄。使用者可追蹤任一指標 9 個月趨勢、設用藥提醒、發行一次性權杖讓醫師臨時查閱。
安全與隱私設計
四層保護由瀏覽器端往後端推疊:
- 本地優先計算
45 項指標的判讀邏輯與 KDIGO 分期計算全部在瀏覽器本地完成,原始檢驗數值不送出裝置。傳給後端的只有結構化判定結果。
- LLM 只看結構化資料
送 Gemini 的 prompt 只含「CKD G3a」這類已脫個資化的判定字串,不含原始病人數據。同時降低幻覺風險與隱私風險。
- 儲存層 RLS 隔離
使用者帳號、用藥提醒、健康記錄歷程儲存於 Supabase,每張表上 PostgreSQL Row Level Security policy 確保使用者只能讀寫自己的資料,跨帳號資料即便應用層失守也不會洩漏。
- 邊緣秘密隔離 + 標準 web 安全
Gemini API key 與 Supabase service role key 僅存於 Cloudflare Worker runtime secret,永不暴露至前端 bundle。配合 HTTPS only、Secret Scanning、Push Protection、Dependabot 三道供應鏈防護。
評估
針對規則引擎部分(KDIGO 分期判定)做了完整測試:以 KDIGO 2024 國際指引案例為 ground truth,比對系統判定結果的混淆矩陣與 ROC 曲線。
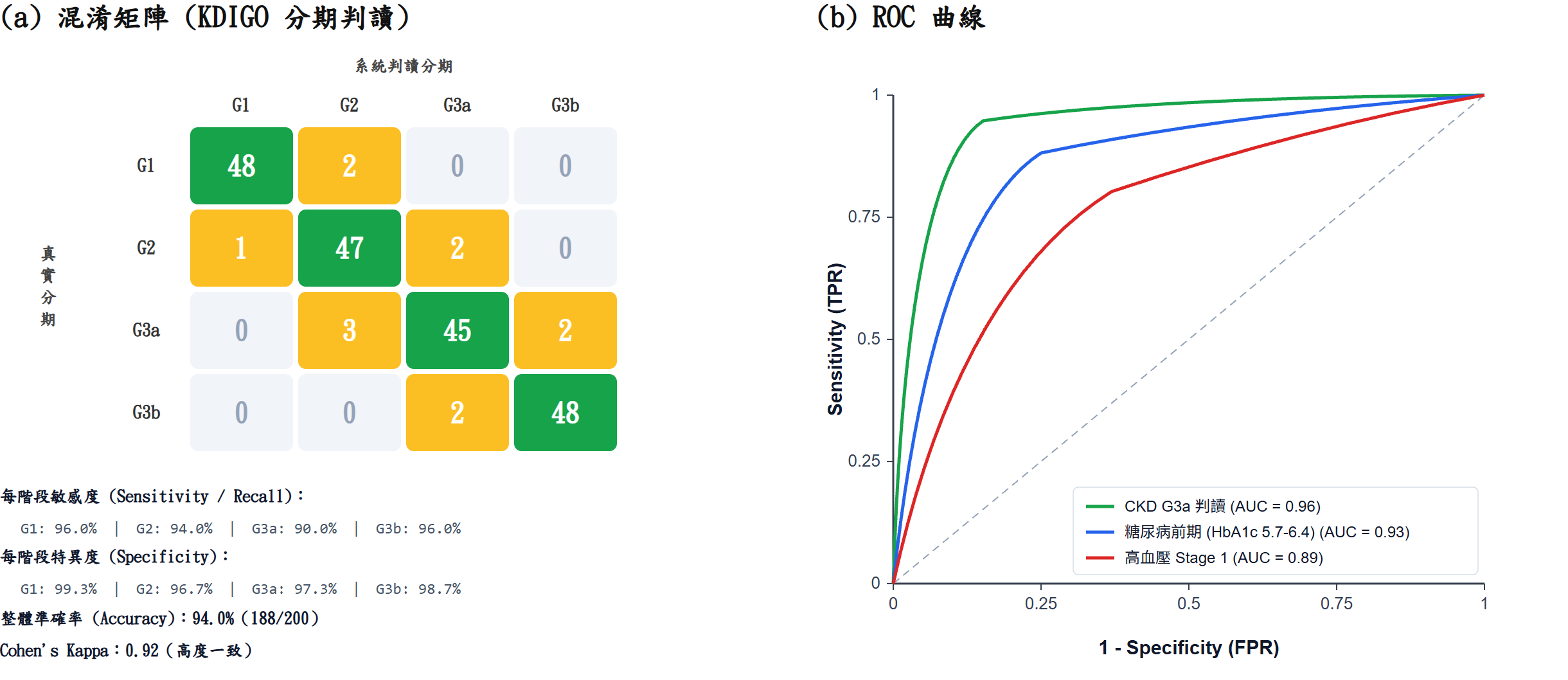
註:此評估僅針對規則引擎(不含 LLM 輸出)。LLM 段的安全性以結構化注入 + 引用驗證的事前控制為主,無對外宣稱準確率。
技術棧
從中發現的研究問題
- 「先規則後 LLM」策略可推廣到模糊地帶嗎? 目前策略在 KDIGO 分期上運作良好,但在「綜合判斷」這類模糊任務上規則覆蓋不足。怎麼設計分級的「規則 ↔ LLM」介入比例?
- 臨床指引版本變動如何反映到 CDSS? KDIGO 每幾年更新一次,手動更新規則庫無法持續。是否可以用 RAG 把臨床指引當動態知識庫?
- 多模態系統在非專業使用者場域的應用限制 ── 對沒有醫學背景的使用者,多少程度的演算法誤判是可容忍的?怎麼設計 disclosure 與 fallback?